![[アップデート] Amazon Redshiftのマルチデータウェアハウス書き込み機能が一般提供開始されたので試してみた](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-63f1274931b942e9a92e601c1127ad73/cfe87ec6d62fa2fc3c474ed4cb2f6c2e/amazon-redshift?w=3840&fm=webp)
[アップデート] Amazon Redshiftのマルチデータウェアハウス書き込み機能が一般提供開始されたので試してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWS事業本部コンサルティング部の石川です。Amazon Redshift のマルチデータウェアハウス書き込み機能がデータ共有が一般提供されました。Amazon Redshift のデータ共有(Data Sharing)において、複数のデータウェアハウス間で書き込みが可能になりました。
ほぼ1年前にプレビューの段階でこの機能を検証していましたが、「USE コマンドを使用してローカル データベースに接続する」方法がうまくいきませんでした。ということで、本日はそのリベンジブログです。
マルチデータウェアハウス書き込み機能とは
Amazon Redshift のデータ共有(Data Sharing) は、複数のデータウェアハウス(Amazon Redshift Provisioned、Amazon Redshift Serverless)間でデータのコピーや移動することなくデータを共有するサービスです。データ共有はデータへのライブアクセスを提供するため、データが更新されてもユーザーは常に最新の一貫性のある情報を見ることができます。
マルチデータウェアハウス書き込み機能とは、データ共有(Data Sharing)したクラスタ間でデータを双方向で書き込みできる機能です。これまでは、データコンシューマーは参照のみでしたが、今回のアップデートで、コンシューマーRedshift(共有される側のRedshift)からデータベースへの書き込みが可能になりました。
コンシューマーRedshiftの共有データにアクセスできるユーザーとグループは、標準のSQLおよび分析ツールを使用して、高性能でデータを検出およびクエリできます。データ共有により、共有データにアクセスするワークロードは互いに分離されます。Amazon Redshiftでデータ共有を使用するための追加コストはありません。
用語の定義
データ共有
データを共有するプロデューサーは、CREATE DATASHARE <sharename>コマンドを使用して1つ以上のデータ共有を作成します。データを共有する単位をデータ共有と呼びます。
データ共有オブジェクト
上記のデータ共有に追加したプロデューサーのオブジェクト(テーブルやビューなど)をデータ共有オブジェクトと呼びます。
プロデューサーRedshift
データを共有するRedshiftを表します。Producer-Consumerパターンのプロデューサーです。
コンシューマーRedshift
データを共有されるRedshiftを表します。Producer-Consumerパターンのコンシューマーです。
名前空間ID(Namespace ID)
ネームスペース毎に付与されたユニークな識別子。
Amazon Redshift でのデータ共有に関する考慮事項
2024年11月26日時点で、Amazon Redshift Database Developer Guideに、Considerations for data sharing in Amazon Redshiftが追加されました。考慮事項の詳細については、以下をご覧ください。
以下では、特に抑えておいたほうが良いポイントについて解説します。
データ共有のためのクラスタ暗号化管理
AWS アカウント間でデータを共有するには、プロデューサー クラスターとコンシューマークラスターの両方を暗号化する必要があります。
データ共有読み取りの制限
データ共有は、プロビジョニングされたすべての RA3 クラスタータイプと Amazon Redshift Serverless でサポートされています。
マルチウェアハウス書き込みの制限
Amazon Redshift でデータ共有書き込みを使用する場合に特に注意すべき制限は次のとおりです。
- 接続
- データ共有データベースに直接接続するか、USE コマンドを実行してデータ共有に書き込む必要があります。3 部構成の表記法も使用できます。USE コマンドは外部テーブルではサポートされていません。
- コンピューティングタイプ
- この機能を使用するには、サーバーレス ワークグループ、ra3.xlplus クラスター、ra3.4xl クラスター、または ra3.16xl クラスターを使用する必要があります。
- 分離レベル
- 他の Serverless ワークグループとプロビジョニングされたクラスターがデータベースに書き込めるようにするには、データベースの分離レベルをスナップショット分離にする必要があります。
サポートされているSQL文
以下はサポートされていないステートメントタイプです。
- コンシューマーからプロデューサーへのクエリの同時実行スケーリングはサポートしていません
- コンシューマーからプロデューサーへのAuto-copyによる自動書き込みはサポートしていません
- プロデューサー クラスター上にZero-ETL 統合テーブルを作成するコンシューマーはサポートしていません。
- データ共有を介したインターリーブドソート キーを持つテーブルへ書き込みはサポートしていません
検証環境
検証用Redshift Serverlessのワークスペース
2つのRedshift Serverlessワークスペースを作成しました。
- プロデューサーのRedshift: producer-ns
- 名前空間ID(Namespace ID): a50a38ac-fdaa-4cc9-94ec-b557dcfc9e36
- コンシューマーのRedshift: consumer-ns
- 名前空間ID(Namespace ID): af80eb3e-456d-4fb4-a8ec-450afca16c93
Redshiftのデータ共有(Data Sharing)では、共有する側(以降、Producerと呼びます)と共有される側(以降、Consumerと呼びます)を2つのRedshiftを準備します。
検証シナリオ
今回は、プロデューサーワークスペースのticketスキーマとそのテーブルのデータ共有を作成して、コンシューマーRedshiftに共有します。コンシューマーRedshiftでは、共有されたデータ共有を用いてデータベースを定義します。
データ共有の作成・設定
プロデューサーRedshiftの設定
データ共有するスキーマ・テーブルの準備
サクッと、サンプルのデータを用意したいので、sample_data_devデータベースのテーブルをコピーします。
dev=# CREATE SCHEMA tickit;
CREATE SCHEMA
dev=# CREATE TABLE tickit.users AS SELECT * FROM sample_data_dev.tickit.users;
CREATE TABLE
dev=# set search_path to tickit;
SET
dev=# show search_path;
search_path
-------------
tickit
(1 row)
dev=# \d
List of relations
schema | name | type | owner
------------+--------------------------------+-------+-------
tickit | users | table | admin
(1 rows)
データ共有の作成
最初にデータ共有を作成します。ここで作成した「データ共有」という器にスキーマやテーブルを追加します。
dev=# CREATE DATASHARE tickit_datashare;
CREATE DATASHARE
dev=# ALTER DATASHARE tickit_datashare SET publicaccessible = TRUE;
ALTER DATASHARE
tickit_datashareに対して、CREATE, USAGEを許可します。
dev=# GRANT CREATE, USAGE ON SCHEMA tickit TO DATASHARE tickit_datashare;
GRANT
データ共有にtickitスキーマの各テーブルを追加
データ共有に共有したいテーブルを追加します。tickit_datashare.userに対して、SELECTとINSERTを付与します。これでconsumerは、読み(SELECT)、書き込み(INSERT)できようになります。
dev=# GRANT SELECT, INSERT ON TABLE tickit.users TO DATASHARE tickit_datashare;
GRANT
作成したデータ共有をコンシューマーRedshiftに共有する
作成したデータ共有は、コンシューマーRedshiftのNAMESPACE(af80eb3e-456d-4fb4-a8ec-450afca16c93)を指定して共有します。
dev=# GRANT USAGE ON DATASHARE tickit_datashare TO NAMESPACE 'af80eb3e-456d-4fb4-a8ec-450afca16c93';
GRANT
これでプロデューサーRedshiftのデータ共有の共有設定は完了です。マネジメントコンソールからはこのように確認できます。
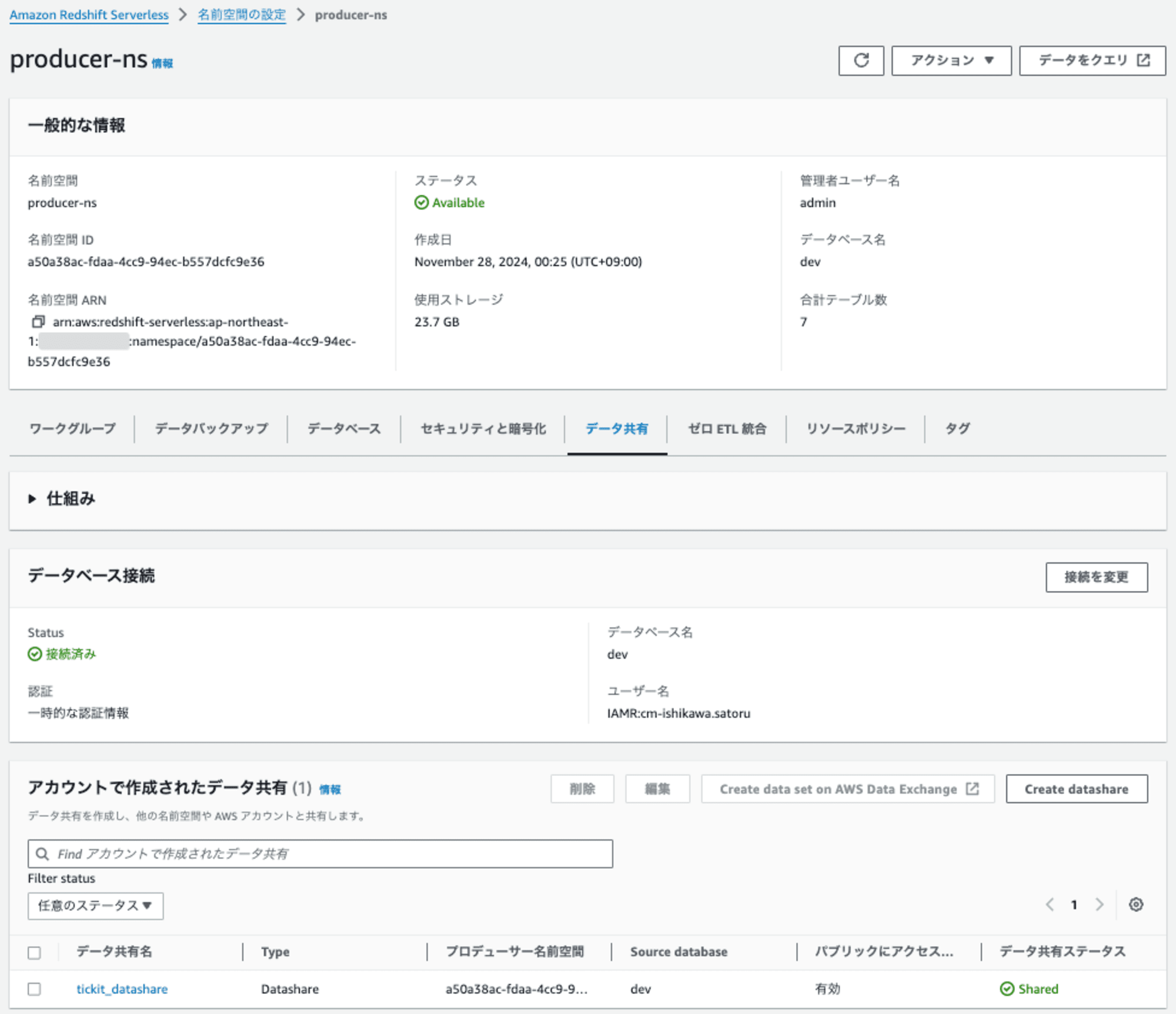
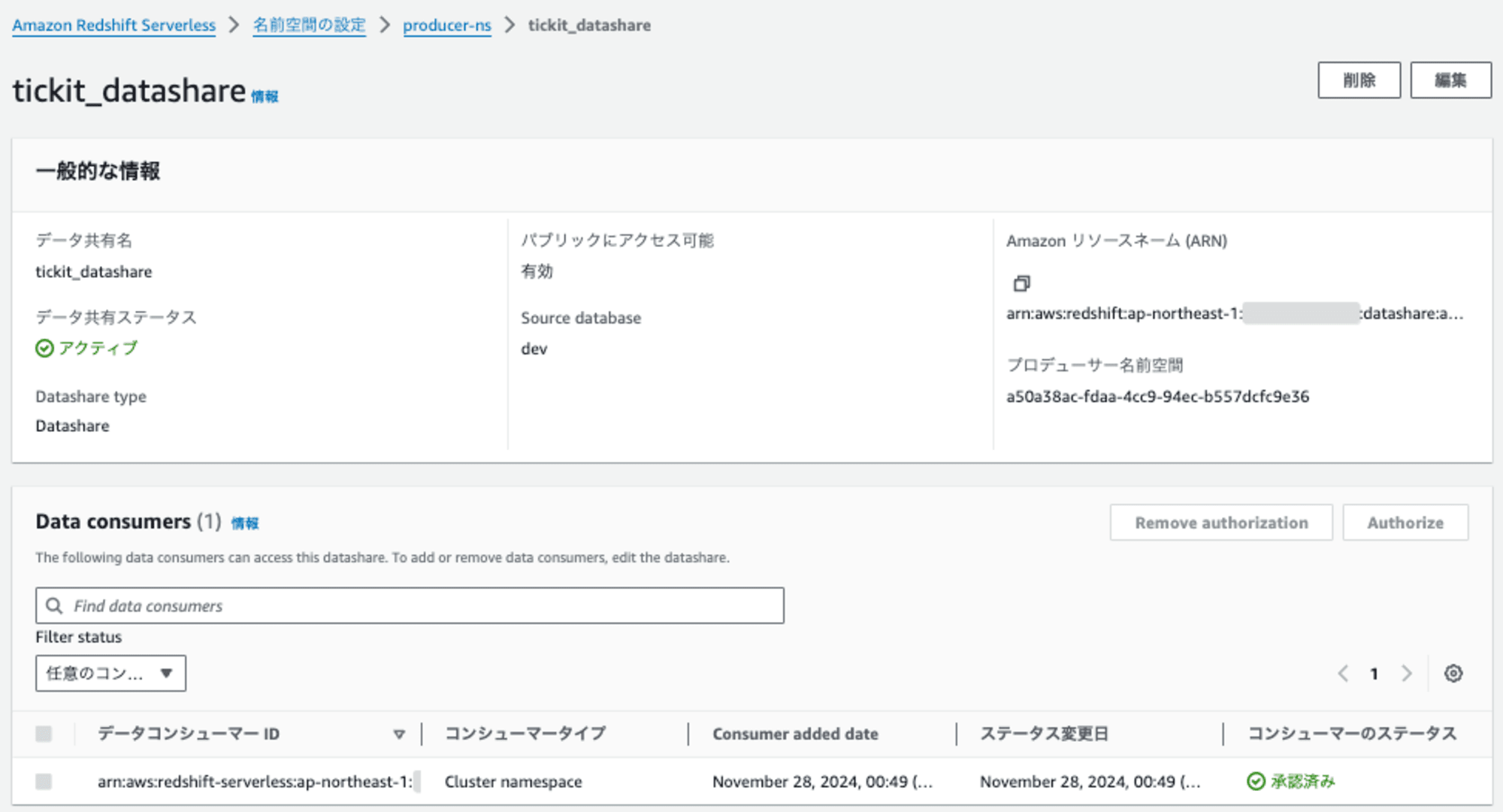
データ共有名(tickit_datashare)をクリックすると、詳細を確認できます。
データ共有したコンシューマーRedshift一覧
プロデューサーRedshiftで作成したデータ共有をどのコンシューマーRedshiftに共有したかを確認できます。
dev=# SELECT * FROM svv_datashare_consumers;
-[ RECORD 1 ]------+-------------------------------------
share_name | tickit_datashare
consumer_account |
consumer_namespace | af80eb3e-456d-4fb4-a8ec-450afca16c93
share_date | 2024-11-27 15:49:36
マネジメントコンソールからはこのように確認できます。

コンシューマーRedshiftの設定
データ共有の一覧の確認
データ共有の一覧を確認します。コンシューマーRedshiftなのでプロデューサーRedshiftが共有してくれたデータ共有が表示されます。コンシューマーRedshiftはデータ共有を参照しているので、share_typeはINBOUNDです。
dev=# SELECT * FROM svv_datashares;
-[ RECORD 1 ]-------+-----------------------------------------------------------------
share_name | tickit_datashare
share_id |
share_owner |
source_database |
consumer_database |
share_type | INBOUND
createdate |
is_publicaccessible | t
share_acl |
producer_account | 123456789012
producer_namespace | a50a38ac-fdaa-4cc9-94ec-b557dcfc9e36
managed_by |
データ共有のオブジェクト一覧
データ共有のオブジェクト一覧も同様に確認できます。コンシューマーRedshiftはデータ共有しているので、share_typeはINBOUNDです。
dev=# SELECT * FROM svv_datashare_objects;
-[ RECORD 1 ]------+-------------------------------------
share_type | INBOUND
share_name | tickit_datashare
object_type | schema
object_name | tickit
producer_account | 123456789012
producer_namespace | a50a38ac-fdaa-4cc9-94ec-b557dcfc9e36
include_new |
-[ RECORD 2 ]------+-------------------------------------
share_type | INBOUND
share_name | tickit_datashare
object_type | table
object_name | tickit.users
producer_account | 123456789012
producer_namespace | a50a38ac-fdaa-4cc9-94ec-b557dcfc9e36
include_new |
データ共有からデータベースを作成
データ共有からデータベースを作成して、共有されたデータの参照します。データベースを作成を作成する際には、プロデューサーRedshiftのNAMESPACE(a50a38ac-fdaa-4cc9-94ec-b557dcfc9e36)とデータ共有でデータベースを作成します。
dev=# CREATE DATABASE consumer_tickit
FROM DATASHARE tickit_datashare OF NAMESPACE 'a50a38ac-fdaa-4cc9-94ec-b557dcfc9e36';
CREATE DATABASE
adminユーザーに作成したデータベースの使用許可を付与
作成したデータベースを参照するにはデータベースの使用許可を付与しなければなりません。
dev=# GRANT USAGE ON DATABASE consumer_tickit TO admin;
GRANT
これでコンシューマーRedshiftのデータ共有の共有設定を確認しようとデータ共有名(tickit_datashare)をクリックすると「datashare not found」になりました。

代替として、Query Editor V2から確認すると、consumer_tickitデータベースが作成できたことが確認できましたので、良しとします。
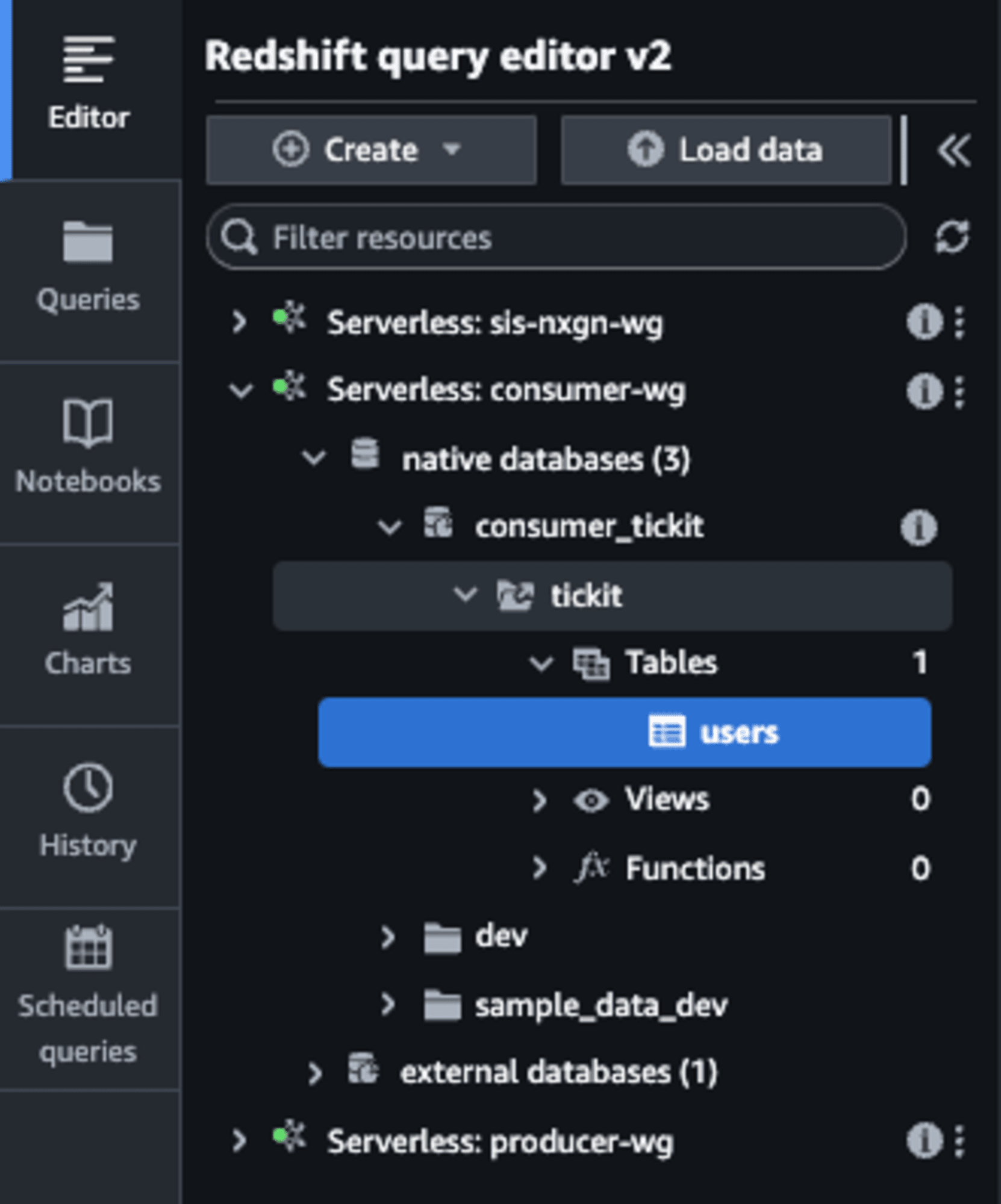
共有データの参照
次は、共有されたデータを参照してみます。Redshiftに接続する際に指定したデータベースによって、データへのアクセス方法が異なります。
別のデータベースからデータを参照
デフォルトのdevデータベースからアクセスする場合は、<database>.<schema>.<object>の3つをドットで修飾した表記法で参照します。所謂、Cross-Databaseです。以下の例では、テーブルのエイリアスを指定してクエリの記述を簡素化しています。
dev=# SELECT * FROM consumer_tickit.tickit.users limit 1;
-[ RECORD 1 ]-+---------------------------------
userid | 260
username | DNU17YEU
firstname | Alyssa
lastname | Bradshaw
city | Saipan
state | PA
email | iaculis.quis.pede@lectusante.org
phone | (593) 655-9880
likesports |
liketheatre |
likeconcerts |
likejazz |
likeclassical | f
likeopera |
likerock | t
likevegas |
likebroadway | f
likemusicals |
データ共有内のオブジェクトへの書き込み
データ共有内のオブジェクトに書き込む方法
プレビューの段階では、データ共有内のオブジェクトに書き込む方法は 2 つあります。なお、将来的には、<database>.<schema>.<object>の3つをドットで修飾した表記法もサポートする予定との記載がありました。
- USE コマンドを使用してローカル データベースに接続する
- Redshift JDBC、ODBC、または Python ドライバーを介して datashares データベースに直接接続します
今回は、1の「USE コマンドを使用してローカル データベースに接続する」方法でデータ共有内のオブジェクトへの書き込みを試みます。
USEコマンドを使用すると、<schema>.<object>の2つをドットで修飾した表記法でデータ共有オブジェクトをクエリし、複数ステートメントのトランザクションを実行できます。複数ステートメントのトランザクションは単一データベース内でのみ実行できます。
USE database;
RESET USE コマンドを実行すると、接続しているデータベースの使用に戻ることができます。
RESET USE;
実際にデータベース「consumer_tickit」に切り替えた様子が以下になります。SHOW USEで接続しているデータベースを確認すると、consumer_tickitに接続していることが確認できます。
dev=# \x
Expanded display is off.
dev=# USE consumer_tickit;
USE
dev=# SHOW USE;
Use Database
-----------------
consumer_tickit
search_pathをtickit変更して、テーブル名(users)だけでデータを参照できることを確認できました。
dev=# show search_path;
search_path
---------------
$user, public
(1 row)
dev=# SET search_path TO tickit;
SET
dev=# SHOW search_path;
search_path
-------------
tickit
(1 row)
dev=# \x
Expanded display is on.
dev=# SELECT * FROM users limit 1;
-[ RECORD 1 ]-+---------------------------------
userid | 260
username | DNU17YEU
firstname | Alyssa
lastname | Bradshaw
city | Saipan
state | PA
email | iaculis.quis.pede@lectusante.org
phone | (593) 655-9880
likesports |
liketheatre |
likeconcerts |
likejazz |
likeclassical | f
likeopera |
likerock | t
likevegas |
likebroadway | f
likemusicals |
接続しているデータベースをもとに戻します。なお、SHOW USEで接続しているデータベースを確認できます。SHOW USEで接続しているデータベースを確認すると、何も設定されていない、つまり元に戻ったことが確認できます。
dev=# RESET USE;
RESET
dev=# SHOW USE;
Use Database
--------------
(1 row)
オブジェクトの書き込み(テーブル追加)
プロデューサーで、CREATEを許可したので、テーブル追加できるか試してみます。
事前にデータベースの切り替えとsearch_pathを更新しました。コンシューマーでCREATE TABLEを実行してテーブルが作成できました。テーブルに参照できることが確認しました。search_pathを設定してテーブル名だけではテーブルを作成できずエラーになります。
dev=# USE consumer_tickit;
USE
dev=# SET search_path TO tickit;
SET
dev=# CREATE TABLE ishikawa (id int, name varchar(256));
ERROR: Internal Service Error (Failed to connect)
dev=# CREATE TABLE tickit.ishikawa (id int, name varchar(256));
CREATE TABLE
dev=# SELECT * FROM ishikawa;
id | name
----+------
(0 rows)
では、プロデューサーでテーブルを確認します。
dev=# SELECT * FROM tickit.ishikawa;
id | name
----+------
(0 rows)
見えました、つまりコンシューマーで作成したテーブル(書き込み)がプロデューサーで確認できたことになります。
オブジェクトの書き込み(テーブルのレコード追加)
引き続き、プロデューサーで、INSERTを許可したので、テーブルのレコード追加できるか試してみます。
まず、コンシューマーでINSERT INTOを実行します。
dev=# INSERT INTO tickit.ishikawa (id, name) VALUES(1, 'consumer');
INSERT 0 1
dev=# SELECT * FROM tickit.ishikawa;
id | name
----+----------
1 | consumer
(1 row)
INSERT INTOできたことが確認できました。
では、プロデューサーでテーブルを確認します。
見えました、つまりコンシューマーで作成したテーブルに対してデータの追加(書き込み)がプロデューサーで確認できたことになります。
dev=# SELECT * FROM tickit.ishikawa;
id | name
----+----------
1 | consumer
(1 row)
ちなみに、プロデューサーでオブジェクトオーナーを確認したところ、ややこしい感じになっています。オブジェクトオーナーは、プロデューサーの方で適切に変更したほうが良さそうですね。
dev=# SET search_path TO tickit;
SET
dev=# \d
List of relations
schema | name | type | owner
--------+----------+-------+----------------------------------------------------------
tickit | ishikawa | table | ds:tickit_datashare_nsp_af80eb3e456d4fb4a8ec450afca16c93
tickit | users | table | admin
(2 rows)
では、さらにプロデューサーからテーブルに対してデータの追加(書き込み)してみます。
dev=# INSERT INTO tickit.ishikawa (id, name) VALUES(2, 'producer');
INSERT 0 1
dev=# SELECT * FROM tickit.ishikawa;
id | name
----+----------
1 | consumer
2 | producer
(2 rows)
オブジェクトオーナーではありませんが、データベース管理ユーザーなので、問題なく書き込みできました。つまり、相互に書き込み(INSERT)できるということです。
コンシューマーからも確認できました。バッチリですね。
dev=# select * from consumer_tickit.tickit.ishikawa;
id | name
----+----------
1 | consumer
2 | producer
(2 rows)
なお、クエリエディタv2からもテーブルが見えています。
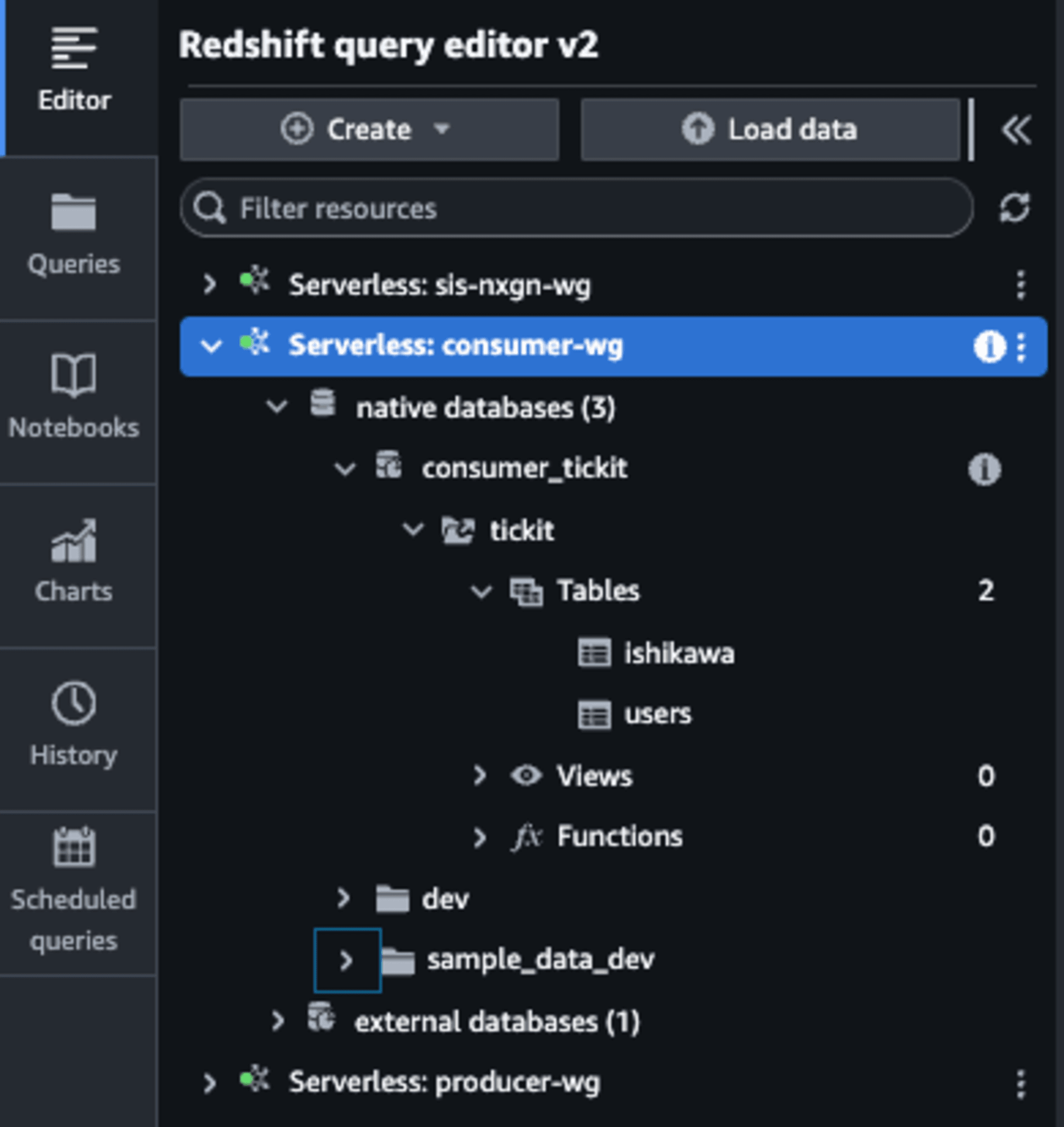
最後に
Amazon Redshiftのマルチデータウェアハウス書き込み機能により、データ共有(Data Sharing)を利用して、複数のRedshiftクラスター間でデータの双方向の書き込みが可能になりました。プロデューサーRedshiftとコンシューマーRedshiftを設定し、データ共有の作成から共有データの参照、さらにはデータの書き込みまでを検証しました。
特に注目すべき点は、コンシューマーRedshiftからプロデューサーRedshiftのデータに対して、テーブルの作成やレコードの追加が可能になったことです。これにより、データの共有と更新がよりシームレスになり、複数のRedshiftクラスター間でのデータ連携がより柔軟になりました。ただし、この機能を使用する際には、クラスターの暗号化や分離レベルなど、すぐに利用可能な状態であるかチェックしたほうが良いでしょう。
この新機能は、大規模なデータ分析環境や複数の組織が互いにデータを提供し合う環境で特に有用であり、データの一貫性を保ちながら、より効率的なデータ管理と分析が可能になると期待されます。









